**出典:**新志源**はじめに:**LeCun のワールドモデルがついに登場しました。誰もが期待していたものと言えます。大型モデルが人間のように世界を理解し、論理的に理解できるようになった今、AGI の実現もそう遠くないのではないでしょうか?ルカン氏は長年にわたり、人間のレベルに到達するAIを理想としており、そのために「ワールドモデル」という概念を提唱しました。最近、ルカン氏は公開演説で GPT の大規模モデルを再度批判しました。確率に基づく自己回帰生成の大規模モデルでは、幻覚の問題をまったく解決できません。 GPT モデルは 5 年も存続しないと直接断言しています。 今日、LeCun はついに夢に一歩近づきました。メタショックは、既存のモデルよりも正確に欠落した画像を解析し完成させることができる「人間に近い」人工知能モデル I-JEPA をリリースしました。 用紙のアドレス:結論: I-JEPA が不足している部分を埋めるとき、世界に関する背景知識が使用されます。他のモデルのように近くのピクセルだけを見るのではなく。「ワールドモデル」の構想が提唱されてから1年以上が経過し、ルカンは自らの星の海を実現しようとしている。現在、トレーニング コードとモデルはオープンソース化されています。この論文は来週のCVPR 2023で発表される予定です。## **LeCun のワールドモデルが登場**今日の最も先進的な AI システムでさえ、いくつかの重要な制限を突破することができません。この束縛層を打ち破るために、Meta のチーフ AI サイエンティスト、Yann LeCun は新しいアーキテクチャを提案しました。 彼のビジョンは、世界がどのように機能するかの内部モデルを学習できるマシンを作成し、より迅速に学習し、複雑なタスクを計画し、新しく不慣れな状況にいつでも対応できるようにすることです。Meta が本日発表した画像結合埋め込み予測フレームワーク I-JEPA モデルは、LeCun の世界モデル ビジョンの重要な部分に基づいた史上初の AI モデルです。I-JEPA は、外部世界の内部モデルを作成することによって学習します。画像を完成させるプロセスでは、ピクセル自体を比較するのではなく、画像の抽象表現を比較します。I-JEPA は、複数のコンピューター ビジョン タスクで優れたパフォーマンスを示しており、他の広く使用されている CV モデルよりも計算効率がはるかに優れています。 ImageNet 線形評価: I-JEPA メソッドは、意味論的な画像表現を学習するための事前トレーニング中に視覚的なデータ拡張を使用せず、他のメソッドよりも少ない計算量で実行します。I-JEPA によって学習された表現は、大規模な微調整を行わずにさまざまなアプリケーションで使用できます。たとえば、研究者らは 72 時間以内に 16 台の A100 GPU を使用して、6 億 3200 万個のパラメーターを備えたビジュアル Transformer モデルをトレーニングしました。ImageNet のローショット分類タスクでは、クラスあたり 12 個のラベル付きサンプルまで、最先端の技術を実現します。他のメソッドは通常、2 ~ 10 倍の GPU 時間を必要とし、同じ量のデータでトレーニングした場合のエラー率が高くなります。## **自己教師あり学習を通じて常識を身につける**一般に、人間は単に受動的に観察するだけで世界についての大量の背景知識を学ぶことができます。推測的には、この種の常識的な情報は、新しい概念、基礎、計画の有効なサンプルを取得するなど、インテリジェントな行動を可能にする鍵であると思われます。 線形読み出しの学習としてのモデル概念の学習I-JEPA (より一般的には、Joint Embedding Prediction Architecture JEPA モデル) に関する Meta の取り組みは、この事実に基づいています。研究者たちが試みたのは、世界に関する常識的な背景知識を取得し、それをアルゴリズムがアクセスできるデジタル表現にエンコードする学習アルゴリズムを考案することです。十分な効率を得るには、システムはこれらの表現を自己監視型で学習する必要があります。つまり、手動で組み立てたラベル付きデータセットからではなく、画像や音声などのラベルなしデータから直接学習する必要があります。より高いレベルでは、JEPA は、同じ入力 (画像またはテキスト) の他の部分の表現に基づいて、入力の一部の表現を予測することを目的としています。JEPA は、画像の複数のビューや拡張表現を 1 つの点に折りたたむ必要がないため、広く使用されている方法 (つまり、不変ベースの事前トレーニング) で発生するバイアスや問題を回避できると大きな期待を寄せています。 ジョイント埋め込みアプローチにより表現の崩壊を回避します同時に、ピクセル値を直接予測するのではなく、高度に抽象的なレベルで表現を予測することにより、JEPA は、生成手法の制限を回避しながら有用な表現を直接学習できることを約束します。対照的に、一般的な生成モデルは、入力モデルの一部を削除または変形することによって学習します。たとえば、写真の一部を消去したり、テキスト段落内の特定の単語を非表示にしたりして、破損または欠落しているピクセルや単語を予測してみます。しかし、このアプローチの重大な欠点は、世界自体は予測不可能であるにもかかわらず、モデルが不足している情報をすべて埋めようとすることです。 その結果、そのようなアプローチは、より高いレベルの予測可能な概念を捉える代わりに、無関係な詳細に焦点を当てすぎるため、人間が決して犯さない間違いを犯す可能性があります。よく知られた例として、生成モデルでは右手を生成するのが難しいということがあります。自己教師あり学習の一般的なアーキテクチャでは、システムはさまざまな入力間の関係を捕捉することを学習します。その目標は、互換性のない入力に高いエネルギーを割り当て、互換性のある入力に低いエネルギーを割り当てることです。 自己教師あり学習のための共通アーキテクチャこれら 3 つの構造の違いは次のとおりです。(a) 結合埋め込み (不変) アーキテクチャは、互換性のある入力 x、y に対しては同様の埋め込みを出力し、互換性のない入力に対しては異なる埋め込みを出力することを学習します。(b) 生成アーキテクチャは、再構築を容易にするために追加の変数 z (おそらく潜在変数) を条件とするデコーダ ネットワークを使用して、互換性のある信号 x から信号 y を直接再構築することを学習します。(c) 結合埋め込み予測アーキテクチャは、予測を容易にする追加の変数 z (おそらく潜在変数) を条件とした予測ネットワークを使用して、互換性のある信号 x から信号 y の埋め込みを予測することを学習します。## **結合埋め込み予測アーキテクチャ**I-JEPA の背後にある原則は、人間の理解により近い抽象表現を通じて欠落情報を予測することです。I-JEPA がセマンティック表現を生成できるようにするためのコア設計の 1 つは、マルチブロック マスキング戦略です。具体的には、チームは、意味情報を含む大きなチャンクを予測することの重要性を実証しました。これらのチャンクは、重要なセマンティック機能をカバーするのに十分なサイズです。 この戦略の利点は、不必要な詳細が削減され、より高いレベルの意味的理解を提供できることです。セマンティック情報の大部分に焦点を当てることで、モデルは画像やテキスト内の重要な概念をより適切に捕捉できるようになり、より強力な予測機能が実現します。画像ベースの結合埋め込み予測アーキテクチャ (I-JEPA) は、単一のコンテキスト ブロックを使用して同じ画像から表現を予測します。このうちコンテキスト エンコーダは、目に見えるコンテキスト パッチのみを処理する Visual Transformer (ViT) です。プレディクターは、コンテキスト エンコーダーの出力を受け取り、ターゲットの位置トークンに基づいてターゲット ブロックの表現を予測する狭い ViT です。 ターゲット表現はターゲット エンコーダの出力に対応し、その重みはコンテキスト エンコーダの重みの指数移動平均によって反復ごとに更新されます。I-JEPA では、予測子は、既知のコンテキスト情報を利用して未知の領域の内容を推測できる原始的な (そして制約された) 世界モデルとみなすことができます。この機能により、モデルは静止画像について推論することができ、画像内の空間的不確実性についての理解を構築できます。ピクセルレベルの詳細のみに焦点を当てる方法とは異なり、I-JEPA は、画像の意味内容をより適切に捕捉するために、目に見えない領域の高レベルの意味情報を予測できます。 予測子が世界のセマンティクスをモデル化することを学習するプロセス各画像について、青いボックスの外側の部分がエンコードされ、コンテキストとして予測子に提供されます。一方、予測子は、青いボックス内で期待される内容を表す表現を出力します。モデルが何を捉えているかを理解するために、チームは確率的デコーダーをトレーニングして I-JEPA の予測表現をピクセル空間にマップし直し、青いボックス内で予測を行ったときのモデルの出力を表示しました。明らかに、予測子は入力すべき意味情報 (犬の頭の上、鳥の足、オオカミの足、建物の反対側) を識別できます。 与えられた画像に対して、4 つのターゲット パッチをランダムにサンプリングし、範囲スケール コンテキスト パッチをランダムにサンプリングして、重複するターゲット パッチを削除します。この戦略では、ターゲット ブロックは比較的セマンティックであり、コンテキスト ブロックは大量の情報を持ちますが、非常に疎であるため、処理効率が高くなります。つまり、I-JEPA は、画像内のオブジェクト部分のローカル位置情報を破棄することなく、オブジェクト部分の高レベル表現を学習することができます。## **高効率、強力なパフォーマンス**事前トレーニングでは、I-JEPA の計算がより効率的になります。まず、複数のビューを生成するために、より計算量の多いデータ拡張を適用する必要がないため、追加のオーバーヘッドが発生しません。第 2 に、ターゲット エンコーダは画像の 1 つのビューを処理するだけでよく、コンテキスト エンコーダはコンテキスト ブロックを処理するだけで済みます。実験では、I-JEPA が人為的なビュー拡張なしで強力な既製の意味表現を学習できることが実証されています。さらに、I-JEPA は、ImageNet-1K 線形検出および半教師あり評価において、ピクセル再構成法およびトークン再構成法よりも優れた性能を発揮します。 事前トレーニング中の GPU 時間の関数としての ImageNet-1k の線形評価パフォーマンスのベンチマークセマンティック タスクに関しては、I-JEPA は、拡張のために人工データに依存する以前の事前トレーニング方法よりも優れたパフォーマンスを発揮します。これらの方法と比較して、I-JEPA は、オブジェクトのカウントや深さの予測などの低レベルの視覚タスクで優れたパフォーマンスを実現します。よりシンプルでより柔軟な誘導バイアス モデルを使用することにより、I-JEPA はより幅広いタスクで使用できます。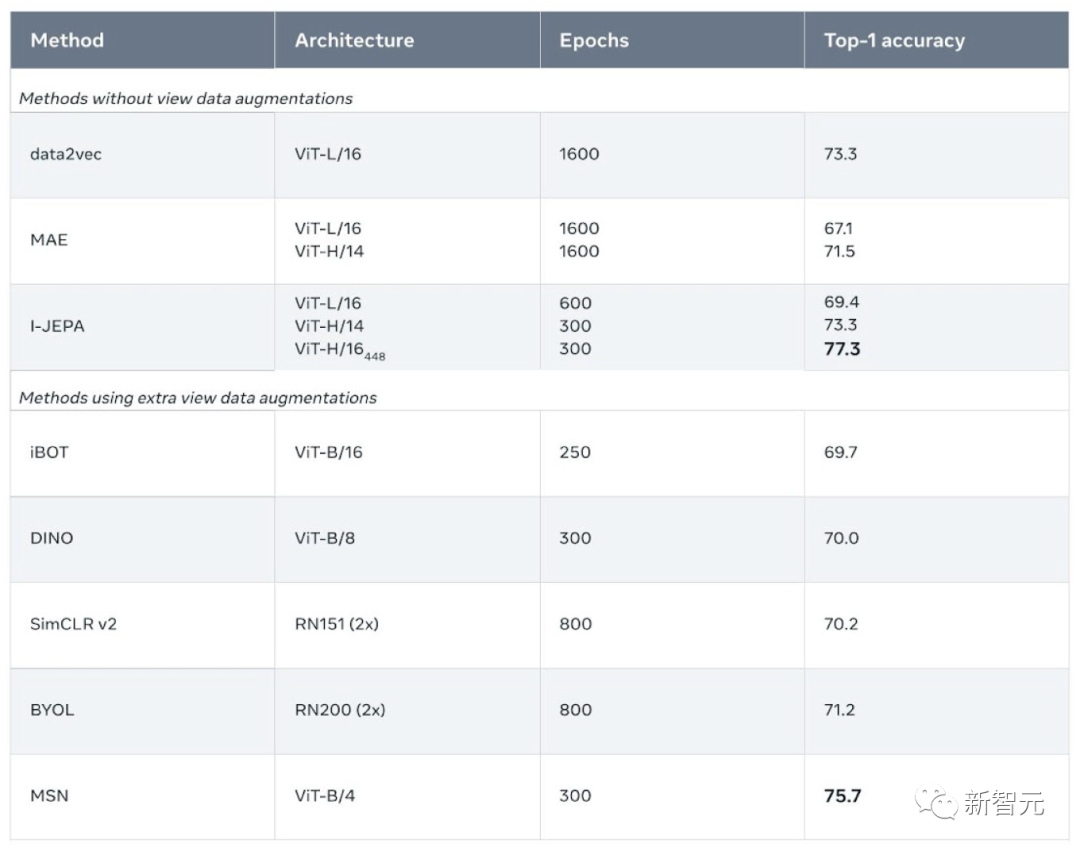 ローショット分類精度: 1% ラベルを使用した ImageNet-1k での半教師あり評価 (クラスあたり約 12 個のラベル付き画像)## **AI は人間の知性をさらに一歩前進させます**I-JEPA は、手作りの知識による追加の支援なしで、既製の画像表現を学習できるアーキテクチャの可能性を示しています。より豊富なモダリティからより一般的な世界モデルを学習するために JEPA を推進することは、特にやりがいのある仕事となるでしょう。たとえば、短いコンテキストからビデオに対して長距離の空間的および時間的予測を行い、音声またはテキストの手がかりに基づいてこれらの予測を条件付けします。 I-JEPA 予測子表現の視覚化: 最初の列には元のイメージが含まれ、2 番目の列にはコンテキスト イメージが含まれ、緑色の境界ボックスには予測子の出力によってデコードされた生成モデルからのサンプルが含まれます。予測子は、位置の不確実性を正確に捕捉し、正確な低レベルの詳細と背景情報を破棄して、正しい姿勢を持つ高レベルのオブジェクト部分を生成します。同チームは、JEPAのアプローチを画像とテキストのペアデータやビデオデータなどの他の領域に拡張することを楽しみにしていると述べている。将来的には、JEPA モデルはビデオ理解などのタスクに興味深い応用が可能になる可能性があります。そしてそれは、世界モデルを学習するための自己教師あり手法を適用および拡張するための重要なステップとなるでしょう。**事前トレーニング済みモデル**## ### **単一 GPU トレーニング**単一 GPU セットアップでは、実装は main.py から始まります。たとえば、構成 configs/in1k\_vith14\_ep300.yaml を使用して、ローカル マシンの GPU 0、1、および 2 で I-JEPA 事前トレーニングを実行するには、次のコマンドを入力します。python main.py \ --fname configs/in1k_vith14_ep300.yaml \ --devices cuda:0 cuda:1 cuda:2注: 結果を再現するには、ViT-H/14 構成を 2048 の有効バッチ サイズで 16 枚の A100 80G グラフィックス カードで実行する必要があります。### **複数の GPU トレーニング**マルチ GPU セットアップでは、実装は main\_distributed.py で開始されます。これにより、構成ファイルの解析に加えて、分散トレーニングに関する詳細を指定できます。分散トレーニングの場合は、SLURM クラスターの例を含む、一般的なオープンソースの送信ツールが必要です。たとえば、configs/in1k\_vith14\_ep300.yaml で指定された事前トレーニング実験構成を使用して 16 枚の A100 80G グラフィックス カードで事前トレーニングするには、次のコマンドを入力します。python main_distributed.py \ --fname configs/in1k_vith14_ep300.yaml \ --folder $path_to_save_submitit_logs \ --partition $slurm_partition \ --nodes 2 --tasks-per-node 8 \ --time 1000## **レビュー**ネチズンはルカン監督の今回の新作に感謝の意を表した。本当に画期的な作品で、感動しました。自己回帰モデルの後継モデルが登場! 私は、フェデレーテッド エンベディング アーキテクチャが AI の未来であり、生成型ではないと信じています。しかし、ちょっと興味があるのですが、マルチモダリティ (テキストと画像のペアだけでなく、ImageBind など) をさらに進めて、VIT エンコーダをエンコーダのようなパーセプトロンに置き換えてみてはいかがでしょうか。 とてもきちんとした仕事。私の理解では、これはマスクされたオートエンコーダーに似ていますが、入力/ピクセル空間ではなく潜在空間で定義されると機能が失われます。ただし、詳細に理解したい場合は、さらに詳しい情報が必要です。 私の脳は論文の 10% しか理解できませんが、I-JEPA が図 3 のターゲット イメージを実際に作成できれば、それは驚くべきことになります。そして最も重要なことは、それが AI 生成の MMORPG に関連しているということです。 このプロジェクトはオープンソース化される予定であり、ネチズンもオープンソース コミュニティに対する Meta の貢献に感謝の意を表しています。 参考文献:
LeCunのワールドモデル登場!世界を理解して半分の絵が完成する初の「ヒューマノイド」モデルのリリースにメタ衝撃、自己教師あり学習に誰もが期待
**出典:**新志源
**はじめに:**LeCun のワールドモデルがついに登場しました。誰もが期待していたものと言えます。大型モデルが人間のように世界を理解し、論理的に理解できるようになった今、AGI の実現もそう遠くないのではないでしょうか?
ルカン氏は長年にわたり、人間のレベルに到達するAIを理想としており、そのために「ワールドモデル」という概念を提唱しました。
最近、ルカン氏は公開演説で GPT の大規模モデルを再度批判しました。確率に基づく自己回帰生成の大規模モデルでは、幻覚の問題をまったく解決できません。 GPT モデルは 5 年も存続しないと直接断言しています。
メタショックは、既存のモデルよりも正確に欠落した画像を解析し完成させることができる「人間に近い」人工知能モデル I-JEPA をリリースしました。
結論: I-JEPA が不足している部分を埋めるとき、世界に関する背景知識が使用されます。他のモデルのように近くのピクセルだけを見るのではなく。
「ワールドモデル」の構想が提唱されてから1年以上が経過し、ルカンは自らの星の海を実現しようとしている。
現在、トレーニング コードとモデルはオープンソース化されています。この論文は来週のCVPR 2023で発表される予定です。
LeCun のワールドモデルが登場
今日の最も先進的な AI システムでさえ、いくつかの重要な制限を突破することができません。
この束縛層を打ち破るために、Meta のチーフ AI サイエンティスト、Yann LeCun は新しいアーキテクチャを提案しました。
Meta が本日発表した画像結合埋め込み予測フレームワーク I-JEPA モデルは、LeCun の世界モデル ビジョンの重要な部分に基づいた史上初の AI モデルです。
I-JEPA は、外部世界の内部モデルを作成することによって学習します。画像を完成させるプロセスでは、ピクセル自体を比較するのではなく、画像の抽象表現を比較します。
I-JEPA は、複数のコンピューター ビジョン タスクで優れたパフォーマンスを示しており、他の広く使用されている CV モデルよりも計算効率がはるかに優れています。
I-JEPA によって学習された表現は、大規模な微調整を行わずにさまざまなアプリケーションで使用できます。
たとえば、研究者らは 72 時間以内に 16 台の A100 GPU を使用して、6 億 3200 万個のパラメーターを備えたビジュアル Transformer モデルをトレーニングしました。
ImageNet のローショット分類タスクでは、クラスあたり 12 個のラベル付きサンプルまで、最先端の技術を実現します。
他のメソッドは通常、2 ~ 10 倍の GPU 時間を必要とし、同じ量のデータでトレーニングした場合のエラー率が高くなります。
自己教師あり学習を通じて常識を身につける
一般に、人間は単に受動的に観察するだけで世界についての大量の背景知識を学ぶことができます。
推測的には、この種の常識的な情報は、新しい概念、基礎、計画の有効なサンプルを取得するなど、インテリジェントな行動を可能にする鍵であると思われます。
I-JEPA (より一般的には、Joint Embedding Prediction Architecture JEPA モデル) に関する Meta の取り組みは、この事実に基づいています。
研究者たちが試みたのは、世界に関する常識的な背景知識を取得し、それをアルゴリズムがアクセスできるデジタル表現にエンコードする学習アルゴリズムを考案することです。
十分な効率を得るには、システムはこれらの表現を自己監視型で学習する必要があります。つまり、手動で組み立てたラベル付きデータセットからではなく、画像や音声などのラベルなしデータから直接学習する必要があります。
より高いレベルでは、JEPA は、同じ入力 (画像またはテキスト) の他の部分の表現に基づいて、入力の一部の表現を予測することを目的としています。
JEPA は、画像の複数のビューや拡張表現を 1 つの点に折りたたむ必要がないため、広く使用されている方法 (つまり、不変ベースの事前トレーニング) で発生するバイアスや問題を回避できると大きな期待を寄せています。
同時に、ピクセル値を直接予測するのではなく、高度に抽象的なレベルで表現を予測することにより、JEPA は、生成手法の制限を回避しながら有用な表現を直接学習できることを約束します。
対照的に、一般的な生成モデルは、入力モデルの一部を削除または変形することによって学習します。
たとえば、写真の一部を消去したり、テキスト段落内の特定の単語を非表示にしたりして、破損または欠落しているピクセルや単語を予測してみます。
しかし、このアプローチの重大な欠点は、世界自体は予測不可能であるにもかかわらず、モデルが不足している情報をすべて埋めようとすることです。
よく知られた例として、生成モデルでは右手を生成するのが難しいということがあります。
自己教師あり学習の一般的なアーキテクチャでは、システムはさまざまな入力間の関係を捕捉することを学習します。
その目標は、互換性のない入力に高いエネルギーを割り当て、互換性のある入力に低いエネルギーを割り当てることです。
これら 3 つの構造の違いは次のとおりです。
(a) 結合埋め込み (不変) アーキテクチャは、互換性のある入力 x、y に対しては同様の埋め込みを出力し、互換性のない入力に対しては異なる埋め込みを出力することを学習します。
(b) 生成アーキテクチャは、再構築を容易にするために追加の変数 z (おそらく潜在変数) を条件とするデコーダ ネットワークを使用して、互換性のある信号 x から信号 y を直接再構築することを学習します。
(c) 結合埋め込み予測アーキテクチャは、予測を容易にする追加の変数 z (おそらく潜在変数) を条件とした予測ネットワークを使用して、互換性のある信号 x から信号 y の埋め込みを予測することを学習します。
結合埋め込み予測アーキテクチャ
I-JEPA の背後にある原則は、人間の理解により近い抽象表現を通じて欠落情報を予測することです。
I-JEPA がセマンティック表現を生成できるようにするためのコア設計の 1 つは、マルチブロック マスキング戦略です。
具体的には、チームは、意味情報を含む大きなチャンクを予測することの重要性を実証しました。これらのチャンクは、重要なセマンティック機能をカバーするのに十分なサイズです。
セマンティック情報の大部分に焦点を当てることで、モデルは画像やテキスト内の重要な概念をより適切に捕捉できるようになり、より強力な予測機能が実現します。
画像ベースの結合埋め込み予測アーキテクチャ (I-JEPA) は、単一のコンテキスト ブロックを使用して同じ画像から表現を予測します。
このうちコンテキスト エンコーダは、目に見えるコンテキスト パッチのみを処理する Visual Transformer (ViT) です。
プレディクターは、コンテキスト エンコーダーの出力を受け取り、ターゲットの位置トークンに基づいてターゲット ブロックの表現を予測する狭い ViT です。
I-JEPA では、予測子は、既知のコンテキスト情報を利用して未知の領域の内容を推測できる原始的な (そして制約された) 世界モデルとみなすことができます。
この機能により、モデルは静止画像について推論することができ、画像内の空間的不確実性についての理解を構築できます。
ピクセルレベルの詳細のみに焦点を当てる方法とは異なり、I-JEPA は、画像の意味内容をより適切に捕捉するために、目に見えない領域の高レベルの意味情報を予測できます。
各画像について、青いボックスの外側の部分がエンコードされ、コンテキストとして予測子に提供されます。一方、予測子は、青いボックス内で期待される内容を表す表現を出力します。
モデルが何を捉えているかを理解するために、チームは確率的デコーダーをトレーニングして I-JEPA の予測表現をピクセル空間にマップし直し、青いボックス内で予測を行ったときのモデルの出力を表示しました。
明らかに、予測子は入力すべき意味情報 (犬の頭の上、鳥の足、オオカミの足、建物の反対側) を識別できます。
つまり、I-JEPA は、画像内のオブジェクト部分のローカル位置情報を破棄することなく、オブジェクト部分の高レベル表現を学習することができます。
高効率、強力なパフォーマンス
事前トレーニングでは、I-JEPA の計算がより効率的になります。
まず、複数のビューを生成するために、より計算量の多いデータ拡張を適用する必要がないため、追加のオーバーヘッドが発生しません。
第 2 に、ターゲット エンコーダは画像の 1 つのビューを処理するだけでよく、コンテキスト エンコーダはコンテキスト ブロックを処理するだけで済みます。
実験では、I-JEPA が人為的なビュー拡張なしで強力な既製の意味表現を学習できることが実証されています。
さらに、I-JEPA は、ImageNet-1K 線形検出および半教師あり評価において、ピクセル再構成法およびトークン再構成法よりも優れた性能を発揮します。
セマンティック タスクに関しては、I-JEPA は、拡張のために人工データに依存する以前の事前トレーニング方法よりも優れたパフォーマンスを発揮します。
これらの方法と比較して、I-JEPA は、オブジェクトのカウントや深さの予測などの低レベルの視覚タスクで優れたパフォーマンスを実現します。
よりシンプルでより柔軟な誘導バイアス モデルを使用することにより、I-JEPA はより幅広いタスクで使用できます。
AI は人間の知性をさらに一歩前進させます
I-JEPA は、手作りの知識による追加の支援なしで、既製の画像表現を学習できるアーキテクチャの可能性を示しています。
より豊富なモダリティからより一般的な世界モデルを学習するために JEPA を推進することは、特にやりがいのある仕事となるでしょう。
たとえば、短いコンテキストからビデオに対して長距離の空間的および時間的予測を行い、音声またはテキストの手がかりに基づいてこれらの予測を条件付けします。
同チームは、JEPAのアプローチを画像とテキストのペアデータやビデオデータなどの他の領域に拡張することを楽しみにしていると述べている。
将来的には、JEPA モデルはビデオ理解などのタスクに興味深い応用が可能になる可能性があります。そしてそれは、世界モデルを学習するための自己教師あり手法を適用および拡張するための重要なステップとなるでしょう。
事前トレーニング済みモデル
単一 GPU セットアップでは、実装は main.py から始まります。
たとえば、構成 configs/in1k_vith14_ep300.yaml を使用して、ローカル マシンの GPU 0、1、および 2 で I-JEPA 事前トレーニングを実行するには、次のコマンドを入力します。
python main.py \ --fname configs/in1k_vith14_ep300.yaml \ --devices cuda:0 cuda:1 cuda:2
注: 結果を再現するには、ViT-H/14 構成を 2048 の有効バッチ サイズで 16 枚の A100 80G グラフィックス カードで実行する必要があります。
複数の GPU トレーニング
マルチ GPU セットアップでは、実装は main_distributed.py で開始されます。これにより、構成ファイルの解析に加えて、分散トレーニングに関する詳細を指定できます。
分散トレーニングの場合は、SLURM クラスターの例を含む、一般的なオープンソースの送信ツールが必要です。
たとえば、configs/in1k_vith14_ep300.yaml で指定された事前トレーニング実験構成を使用して 16 枚の A100 80G グラフィックス カードで事前トレーニングするには、次のコマンドを入力します。
python main_distributed.py \ --fname configs/in1k_vith14_ep300.yaml \ --folder $path_to_save_submitit_logs \ --partition $slurm_partition \ --nodes 2 --tasks-per-node 8 \ --time 1000
## レビュー
ネチズンはルカン監督の今回の新作に感謝の意を表した。
本当に画期的な作品で、感動しました。自己回帰モデルの後継モデルが登場!