Polymarketにおけるデータインデックス化の悲劇
要約
GCC Researchによる「Crypto Tragedy of the Commons」シリーズへようこそ。
本シリーズでは、Web3の基盤をなすブロックチェーン・パブリックグッズが、分散化という本来の理念から逸脱しつつある現状に焦点を当てます。これらはエコシステムの土台でありながら、インセンティブの不全、ガバナンス課題、中央集権化のリスクなど、さまざまな問題に直面しています。分散化の理想と、現実的な運用の安定性に必要な冗長性との間で、今まさに大きな緊張が生じています。
今回は、Ethereumを代表するアプリケーションであるPolymarketとそのデータインデックスツールに注目します。本年初めから、トランプ氏の選挙オッズに絡むオラクル操作疑惑、ウクライナのレアアース賭博、ゼレンスキー大統領のスーツカラーにまつわる政治賭博など、Polymarketはたびたび大きな論争の渦中にありました。これらの争点は、資金規模・影響力の大きさから無視できないものとなっています。
しかし、この「分散型予測市場」が、最も重要なデータインデックス層において、本当に分散化を実現できているのでしょうか。また、The Graphのような分散型インフラがなぜ十分な支持を集められないのでしょうか。実用的かつ持続可能なパブリック・データインデックスの解決策として、私たちは何を目指すべきでしょうか。
I. 中央集権型データプラットフォーム障害の連鎖的影響
2024年7月、Web3開発者向けにリアルタイムのブロックチェーンデータインフラを提供するGoldskyで、6時間に及ぶ障害が発生しました。これによりEthereumエコシステムの広範な領域がダウンし、DeFiのフロントエンドがユーザーのポジションや残高を表示できなくなり、Polymarket等の予測市場も正確なデータ表示ができなくなりました。ユーザーから見ると、さまざまなプロジェクトのインターフェースが全く使えない状態となりました。
こうした事態こそ、本来分散型アプリケーションによって防がれるべきものです。ブロックチェーン設計の根本動機は、単一障害点の排除にあります。今回のGoldsky障害で明らかになったのは、ブロックチェーン自体は分散化されていても、多くのオンチェーンアプリケーションを支えるインフラが依然、中央集権的であるという現実です。
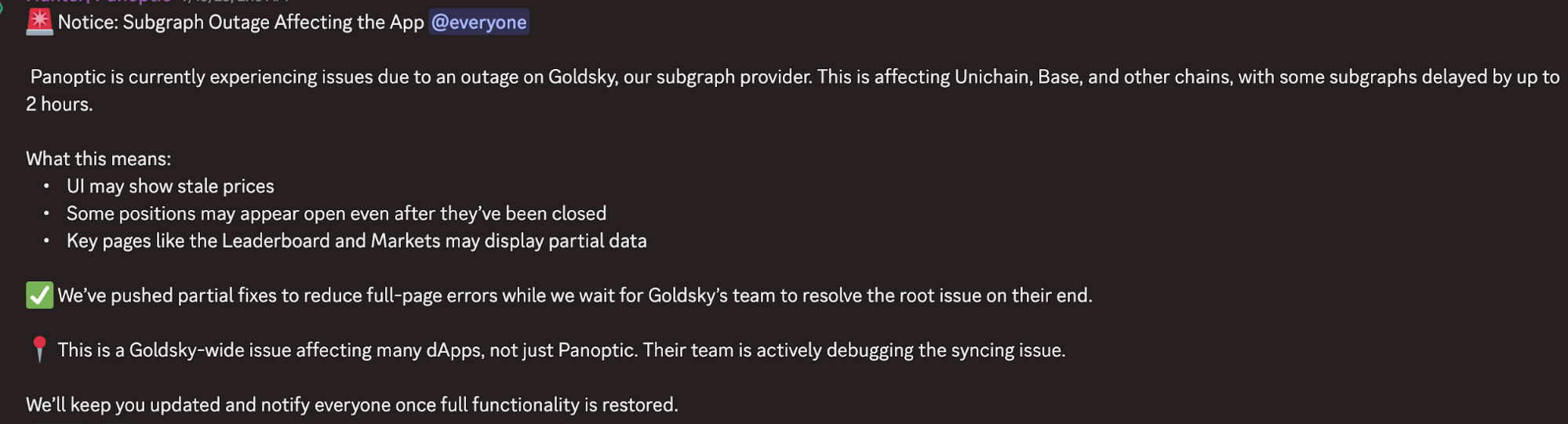
その根本要因は、ブロックチェーンのデータインデックスやクエリがデジタル公共財(非排他性・非競合性)であり、ユーザーはほとんどの場合それらを無料もしくは極めて低コストで利用できると期待していることにあります。しかし、このインフラの維持には、ハードウェア・ストレージ・通信帯域・エンジニアリングといった持続的な投資が必要です。安定的な収益モデルがなければ、この分野は「勝者総取り」の構造となりやすく、スピードや資本力で優位なプロバイダーに開発者のクエリが集中し、結局新たな依存点が生まれてしまいます。Gitcoinをはじめとする非営利団体も「オープンソースインフラは数十億ドル規模の価値を生む一方で、開発者は生活資金にも苦しむ」と警告しています。
この問題の教訓は明白です。分散型の世界には、パブリックグッズへの資金調達、インセンティブの再設計、コミュニティ主導モデルなど、Web3インフラの多様化と新たな中央集権の芽を摘むための迅速な取り組みが不可欠です。DApp開発者にはローカルファーストのアプローチを奨励し、技術コミュニティにはインデクサがオフラインでもDAppのデータ取得障害に柔軟に対応できる設計を強く推奨します。
II. あなたのDAppのデータは実際にどこから来ているのか?
Goldsky障害のような事例を考察するには、DAppの内部構造をより深く理解する必要があります。多くのユーザーは、「オンチェーンコントラクト」と「フロントエンドUI」の2要素しか意識していません。普段はEtherscanで取引状況を確認し、フロントエンドでデータを閲覧・UIを通じてコントラクト操作を行っています。しかし、そのフロントエンドのデータ供給元はどこなのでしょうか?
データ取得サービスの本質的役割
たとえば、ユーザーのポジションや証拠金、債務情報を表示するレンディングプロトコルを開発する場合を想定しましょう。フロントエンドが単純にブロックチェーンから直接データを取得したとすると、多くのプロトコルコントラクトは「ユーザーアドレスごとの全ポジションの一括取得」には対応しておらず、個別のポジションID単位でしか参照できません。そのため、ユーザーごとのポジション一覧を表示するには、全オープンポジションを総なめしてから該当ユーザー分だけを抽出する必要があり、これは数百万件に及ぶ台帳から手作業で検索するのと同じです。技術的には可能でも、非常に非効率かつ遅くなります。実際、大規模DeFiプロジェクトがローカルノードから全データをバックエンドで取り出す場合、数時間かかることもあります。
そこで必要となるのが、データアクセスを大幅に効率化する専用インフラです。Goldskyのようなプロバイダーは、インデックス作成サービスによってアクセスを飛躍的に高速化します。下図は、こういったサービスのおかげでアプリケーションが取得可能なデータ例を示しています。

「The GraphはEthereumで分散型データ取得を提供しているのでは?」と疑問に思う方もいるでしょう。Goldskyとの違いは何か、なぜ多くのDeFiプロジェクトがThe GraphよりGoldskyを選ぶのでしょうか。
The Graph・Goldsky・SubGraphの関係性
要点を整理します:
- SubGraphは開発者がオンチェーンデータを読み取り集計し、フロントエンド表示に最適化するためのフレームワークです。
- The Graphは、このSubGraphフレームワーク(AssemblyScriptベース)を提供する分散型データ取得プラットフォームであり、開発者はSubGraphを用いてコントラクトイベントをデータベースに記録し、GraphQLやSQLでクエリ可能にします。
- SubGraphを運用する事業者がSubGraphオペレーターであり、The GraphもGoldskyもサブグラフプロジェクトのホスティングサービスを担っています(サブグラフコードはサーバーで稼働する必要があるため)。Goldskyのドキュメント抜粋は下記の通りです。
なぜ複数のSubGraphオペレーターが存在するのでしょうか?
サブグラフフレームワークは「ブロックデータ抽出とDB書き込みの仕様」までしか決めておらず、データフローや出力部分はオペレーターが各自で独自実装するためです。
そのため、各オペレーターは独自のノード改修やパフォーマンス最適化を行います。The Graphは高速インデックス化にFirehouseを採用し、Goldskyはコアサブグラフランタイムをクローズドソースで運営しています。
The Graphはサブグラフ・オペレーターの分散型ハブ的役割を果たします。たとえば、Uniswap v3用サブグラフは複数のオペレーターがサポートしており、The Graphはユーザーがサブグラフコードを投稿し、複数運営者の協働で取り扱うマーケットプレイスとなっています。
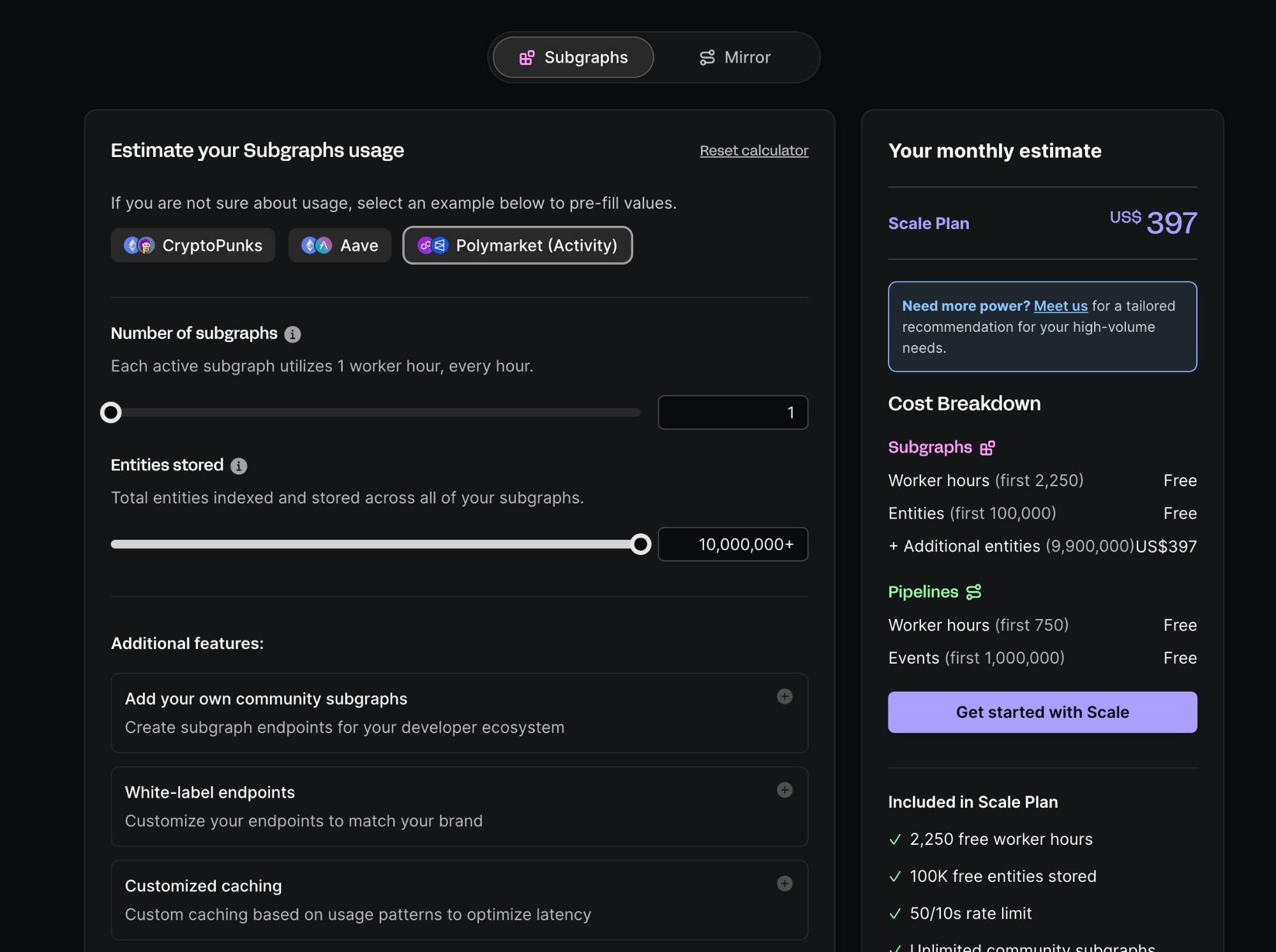
Goldskyの価格体系
Goldskyは従来型のSaaSモデルで、リソース利用量に応じて料金が発生します。開発者にはおなじみの仕組みです。下図はGoldskyの料金計算例です。
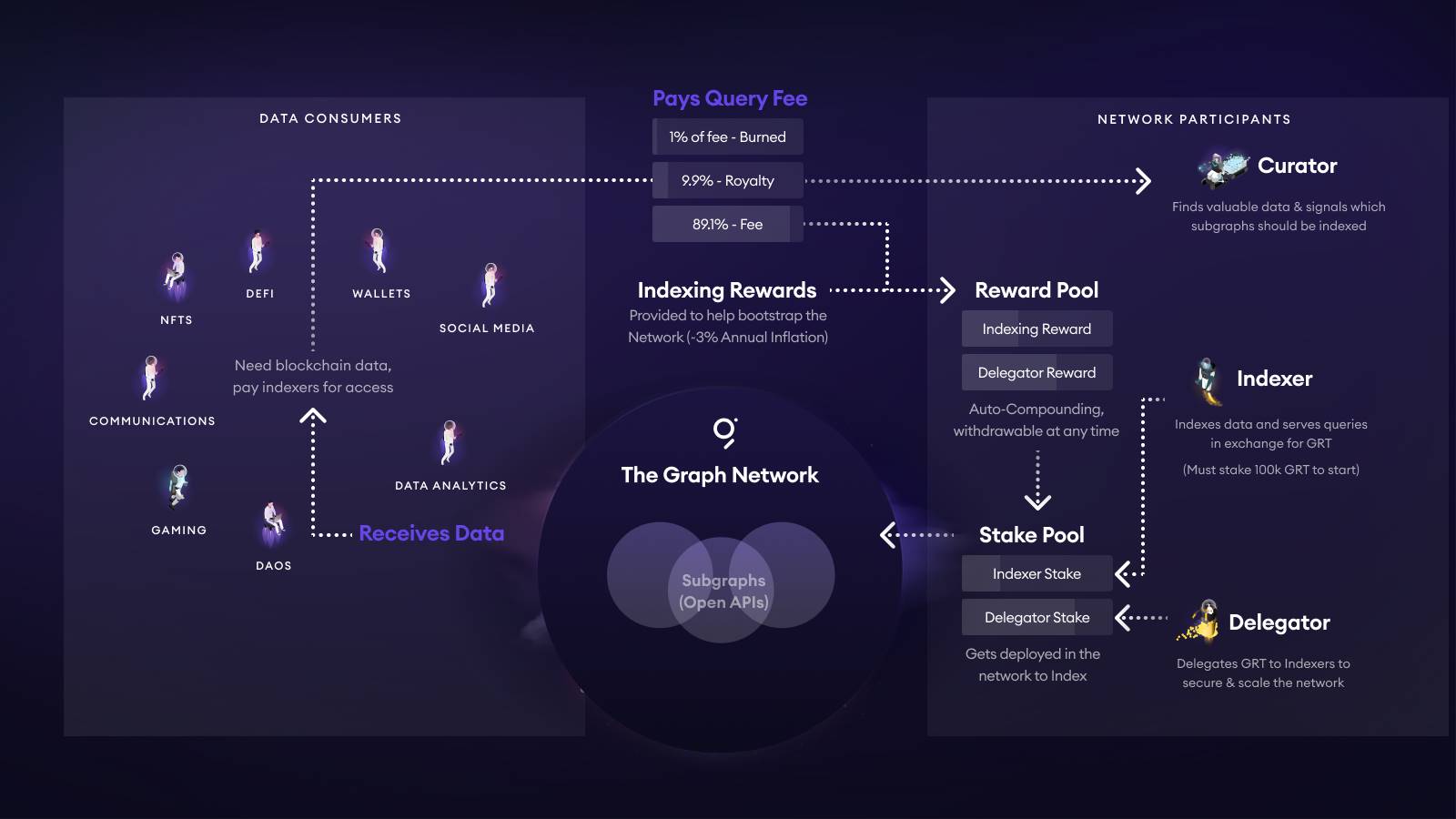
The Graphの価格体系
The Graphは独自の料金体系で、クエリ手数料や報酬インセンティブがGRTトークノミクスに組み込まれています。概要は以下の通りです。
- サブグラフへのクエリごとに手数料が分配され、1%のGRTがバーン、10%がキュレーター(主に開発者)のプール、約89%がインデクサ・デリゲーターへアルゴリズム配分されます。
- インデクサは最低10万GRTのステークが必要で、誤ったデータを返すとペナルティ。デリゲーターはインデクサにGRTを預けて報酬の一部を得ます。
- キュレーター(しばしば開発者)は自身のサブグラフにGRTをステークし、より多くのインデクサリソースを引きつけます。目安として5,000~10,000GRTのステークが推奨されています。
クエリ手数料:
The Graphでは、開発者がAPIキー登録・GRT前払いのうえ、リクエストごとに課金されます。
シグナル・ステーキング手数料:
サブグラフをインデックス化するには、開発者がGRTをステークして価値シグナルを送り、十分なGRT(例:10,000)に到達するとインデクサが対応を開始します。
テスト中は、The Graphのステージングオペレーターで無料デプロイ可能ですが、本番利用にはネットワーク公開が必須となり、インデクサがシグナルに基づいて自発的にインデックス化を選択します。
なぜトークンベース課金は開発者(および経理)に敬遠されるのか
多くのプロジェクトでは、The Graphの運用フローが複雑化しています。GRT購入自体はWeb3チームにとって容易ですが、キュレーションプロセスは遅く、見通しが立てにくいのが現状です。主な課題は以下の2点です:
- 不透明性:開発者がどれほどGRTをステークすべきか、インデクサがサブグラフを取り扱うまでの期間も明確な目安がありません。
- 経費処理の煩雑さ:トークンベースの課金設計により、企業・会計部門でのコスト管理や費目区分が難しくなります。
「中央集権のほうが便利なのか?」
多くの開発者にとってGoldskyは分かりやすく、料金体系も明快で、支払い後即時サービスが確約され、不透明要素も最小限です。Web3において単一インデックスプロバイダーへの依存が加速しているのはこうした理由によります。
The GraphのGRTトークノミクスは理念としては評価されるものの、その煩雑さが開発者の利用障壁となっており、特にキュレーション・ステーキング等はシンプルな決済インターフェースの裏側に隠蔽されるべきだと考えます。
この課題は個人の感想にとどまりません。著名スマートコントラクトエンジニアでSablier創設者のPaul Razvan Berg氏も、サブグラフ公開やGRT決済のUI・UXが極めて悪いと公に批判しています。
III. データインデックス障害への既存ソリューション
データインデックスの単一障害点に対して、エコシステムはどのように対処すべきでしょうか。前述のとおり、開発者はThe Graphを利用する選択肢がありますが、API利用にはGRTのステーキングやキュレーション作業が伴います。
EVMエコシステムにはさまざまなデータインデックス代替手段があります。参考情報としてはDuneのThe State of EVM Indexing、rindexerのEVM Indexing Tools Overview、最近の関連スレッドが挙げられます。
なお、Goldsky障害の具体的な技術的原因については本稿では取り上げません。Goldskyのインシデントレポートによれば、詳細はエンタープライズ顧客にのみ開示されており、インデックス済データのDB書き込み時に問題が発生し、AWS社と連携してアクセス回復に至ったと伝えられています。
有効な代替手法としては次のようなものがあります:
- ponder:シンプルで導入しやすく、自己ホスト型で運用可能なデータインデックスツール。開発者は自身でインフラを用意して起動できます。
- local-first:DAppはネットワーク接続がなくても利用できるべきだとする開発思想。ブロックチェーン領域では、インデクサが停止していてもチェーンと接続可能ならユーザー体験を維持することを目指します。
Ponder:DIY型データインデックス
ponderを推奨する主な理由は以下の通りです:
- ベンダーロックインがない:個人開発者によるツールで、Ethereum RPCエンドポイントとPostgresDBさえ用意すれば、マネージドサービス不要で利用可能です。
- 優れた開発体験:TypeScriptベースでViemライブラリを活用し、扱いやすい設計(筆者も多数利用しています)。
- 高いパフォーマンス性。
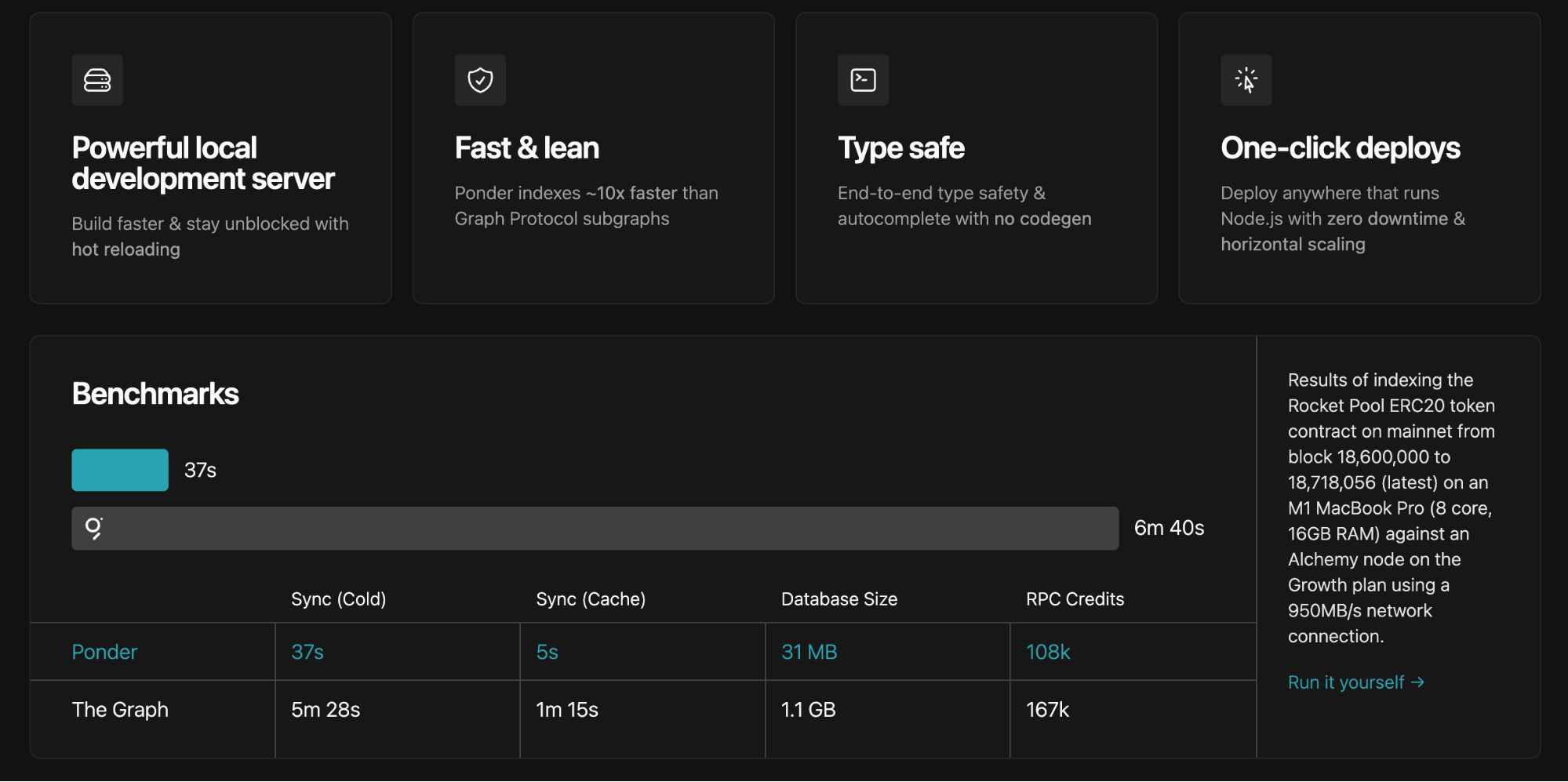
欠点として、開発速度が速いため時に後方互換性が崩れる場合があります。詳細や推奨運用方法については、公式ドキュメントを参照してください。
また、ponderは近年「分離理論」に沿った商用化にも着手しています。
ポイントを整理すると、パブリックグッズは万人の利益となりますが、料金を課すことで周辺ユーザーの排除による全体福利の低下(パレート効率未達)が生じます。理論上は差別化課金による最大余剰化も可能ですが、現実のコストや実装難度は高いです。分離理論の発想では、同質なサブグループのみを分離して課金し、それ以外の利用者は影響を受けません。
ponderによる実装例:
- 利用には相応の技術知識が必要で、外部依存サービス(RPCやDB)のセットアップはユーザー自身が行います。
- 運用維持も自己責任(負荷分散用プロキシ設定やインスレッドデータ取得など)、一部ユーザーには難易度が高い場合も。
- 現在は、Marbleによる自動デプロイβも提供されており、ユーザーはコード提出でワンクリック展開が可能です。
この方式により、「利便性重視層」はMarbleのホスト型サービス(有料)を利用し、他のユーザーは従来通りセルフホスト方式で無料利用できます。
PonderとGoldsky利用層の違い:
- セルフホスト型・完全パーミッションレスなツール(ponder)は、小規模プロジェクトで柔軟性や自主性を重視するケースで人気です。
- 大規模プロジェクトや高可用性・冗長性が必須の場合は、Goldskyのようなマネージドサービスが選択されています。
いずれの運用形式にもリスクがあります。Goldsky障害を踏まえ、開発者はバックアップとして自前のponderインデクサも用意すべきです。また、ponder利用時はRPCレスポンスの妥当性確認も重要です。たとえば、safeによって最近発生した事例では、不正なRPCデータでインデクサがクラッシュしました。Goldsky障害が同様の原因かは不明ですが、影響の可能性は否定できません。

ローカルファースト開発パラダイム
local-firstは近年注目を集める開発手法であり、要件は次の2点です:
- オフライン時の利用可能性
- クライアント間の協調作業
local-first技術論ではCRDT(Conflict-free Replicated Data Types)が語られます。これは分散編集・自動衝突解決のためのデータ構造で、端末間データ整合性を保証する軽量合意プロトコルとして機能します。
ブロックチェーン開発では、こうした要件を緩和し、主目的は「インデックスサービスがダウンしても最低限の機能を維持すること」となります。チェーン自体がもともとクライアント間の整合性を保証しているためです。
実際には、ローカルファーストDAppには以下の特徴が求められます:
- 残高・ポジションなど主要情報はローカルキャッシュしておき、インデクサ停止時でも直近の状態を表示
- 段階的なデグレード――インデクサ停止時は一部データをRPCから直接取り出し、最小限のリアルタイムオンチェーンデータは表示可能にする
このアプローチによって、アプリの耐故障性は著しく向上します。理想を言えば、全ユーザーが自前でローカルノードを運用し、TrueBlocks等のツールで直接データ取得できるDAppがベストです。分散型・ローカルインデックスの議論については、こちらのスレッドも参考にしてください。
IV. 結論
Goldskyの6時間障害はWeb3エコシステム全体に強い警鐘を鳴らしました。ブロックチェーン自体は分散化と堅牢性を備えているものの、アプリケーションレイヤーでは中央集権型インフラへの依存が残り、新たなシステムリスクが浮上しています。
本稿では、The Graphが広く評価されるもののGRTトークノミクスの複雑さや開発者負担から十分に普及していない現状を明らかにしました。また、より堅牢なデータインデックス体制のため、セルフホスト型フレームワーク(ponder)のバックアップ活用や、その商用的な展開事例も紹介しました。さらに、インデクサが停止してもDAppの利便性を維持するlocal-firstパラダイムの実践についても提案しています。
Web3開発者の間では、データインデックスの単一障害点が重大な脆弱性であると認識が広がりつつあり、GCCはコミュニティ全体に対し、本質的なインフラ課題への集中と、分散型データインデクサの試行や、インデクサ停止時もフロントエンドが動くDApp設計への取り組みを強く呼びかけます。
免責事項:
- 本記事はTechFlowからの転載です。著作権は原著者のshew氏に帰属します。転載に関するご懸念がある場合は、Gate Learnチームまでご連絡ください。
- 免責事項:本記事の見解・意見は著者個人のものであり、投資助言ではありません。
- Gate Learnチームによる翻訳記事の無断複製・転載・盗用は禁止されており、必ずGate.comへの正しい帰属表示が必要です。
関連記事


ブロックチェーンについて知っておくべきことすべて

ステーブルコインとは何ですか?

流動性ファーミングとは何ですか?

Cotiとは? COTIについて知っておくべきことすべて
